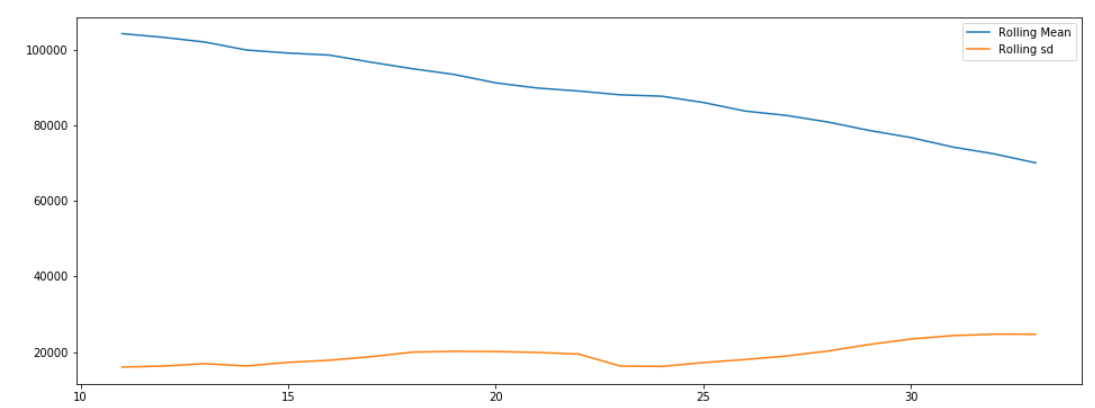
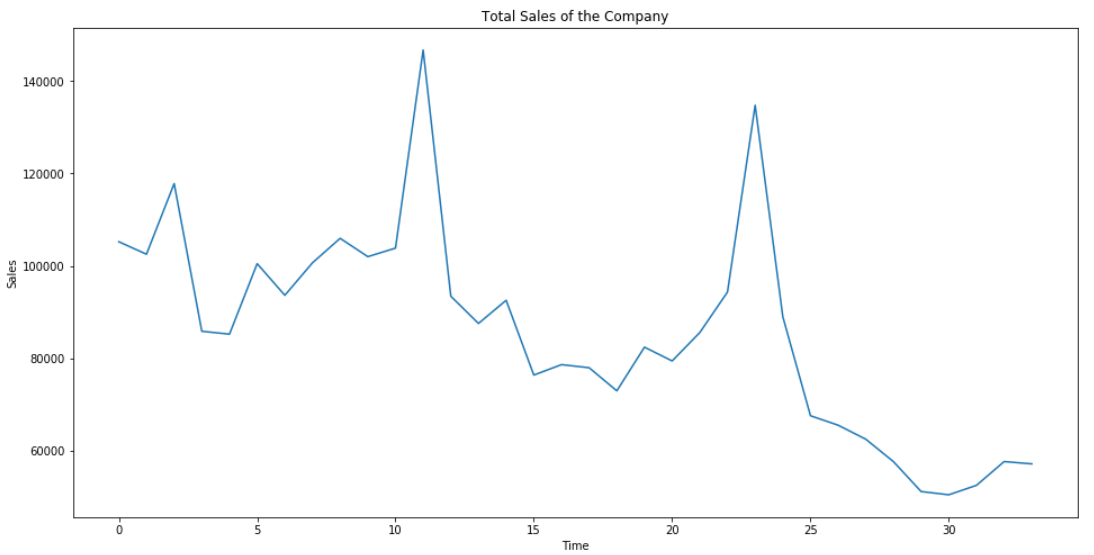
When we have time series data we may want to decompose it into component parts. Python makes this easy with the Statsmodel library’s function, seasonal_decompose(). We are going to assume a multiplicative relationship between the data. Let’s use it:
import statsmodels.api as sm res = sm.tsa.seasonal_decompose(ts.values, freq=12, model="multiplicative") fig=res.plot()
This returns the following graphs:

We can see that the series is trending down and has a strong seasonal component to it. After the trend and seasonality is removed we are left with the residual data which doesn’t seem to exhibit and strong patterns.